1 - Problems
Depth perception from cameras is paramount for many application fields, such as those concerning the autonomous navigation of agents in complex scenarios or robotic tasks.
While monocular depth estimation using conventional cameras has made impressive progress, traditional image sensors suffer from inherent limitations:
Motion blur: caused by the slow acquisition rate when capturing fast-moving scenes. Low HDR: standard cameras struggle in environments with extreme lighting variations, leading to over- or under-exposed images. Discrete framerate: fixed temporal resolution may miss critical transitions between frames, especially during rapid motion.
Event cameras offer a compelling alternative. These bio-inspired sensors asynchronously record brightness changes at the pixel level, yielding high temporal resolution and wide dynamic range. However, this advantage comes at a cost:
Sparse data: events are triggered only at edges or areas with sufficient motion, making the representation incomplete and challenging for dense prediction tasks. Missing large datasets: collecting dense ground-truth depth for event data is expensive and technically demanding, limiting the availability of labeled datasets.
As a result, learning accurate, dense, and robust monocular depth from event data remains a significant challenge—especially in the absence of large-scale annotated datasets.
|
2 - Proposal
To overcome the limitations of event-based monocular depth estimation, we propose a novel cross-modal learning paradigm that leverages the power of Vision Foundation Models (VFMs) trained on standard RGB images. Our goal is to transfer their robust depth prediction capabilities to the event domain, where data is sparse and labeled supervision is limited.
Our approach is based on two key ideas:
-
Cross-modal distillation: we extract dense proxy depth maps from aligned RGB images using a powerful pre-trained VFM (Depth Anything v2), and use them as supervision to train event-based depth models—without requiring ground-truth depth labels.
-
VFM adaptation: we adapt frame-based depth models to work directly on event data, either using a lightweight vanilla architecture or a novel recurrent extension tailored to the sequential nature of events.
This proposal enables effective event-based monocular depth estimation with no expensive hand-crafted supervision. It bridges the modality gap between images and events, and unlocks the potential of large-scale vision models in scenarios where annotated data is scarce.
|
3 - Method
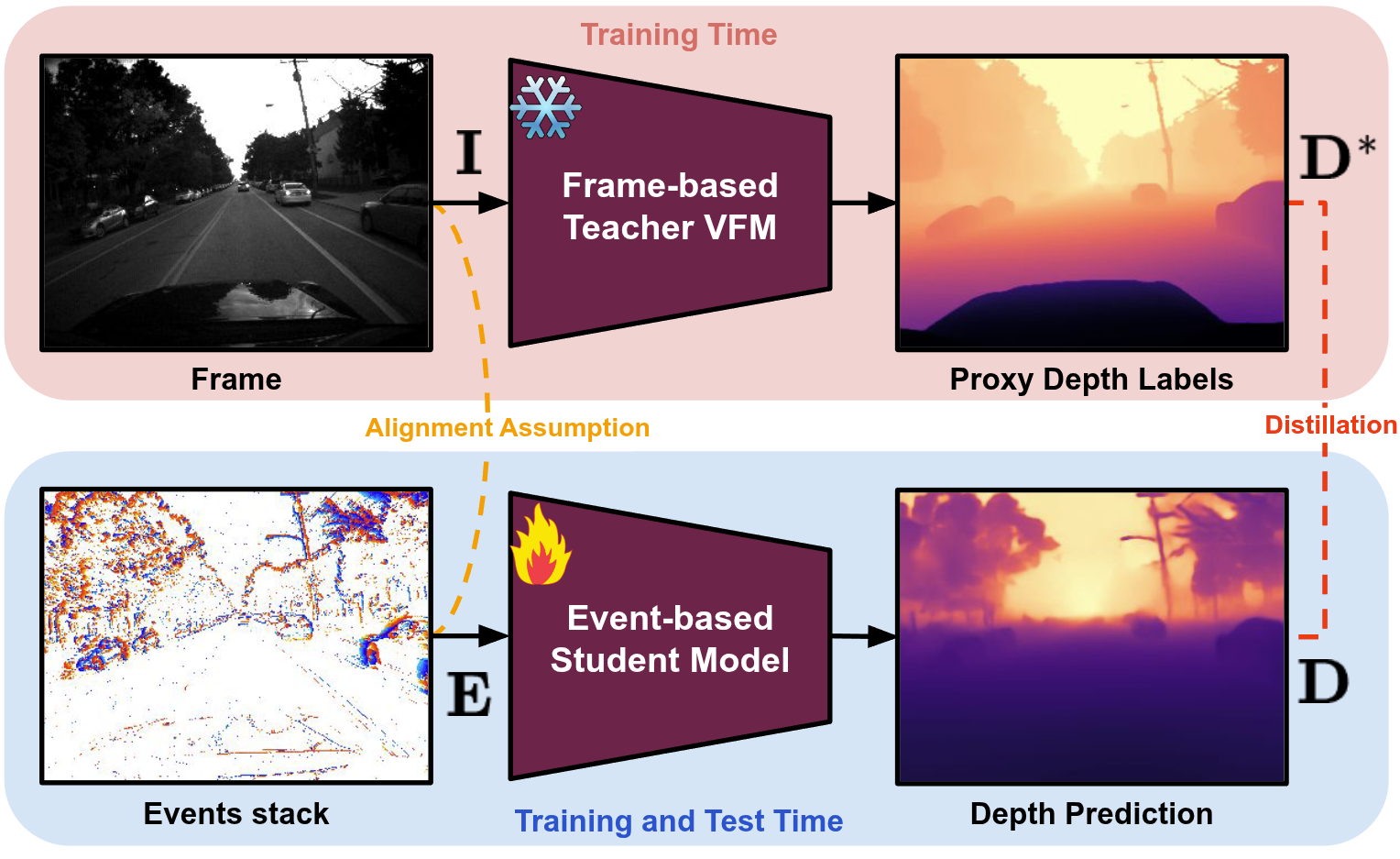
Our framework is designed to bridge the modality gap between conventional images and event streams for monocular depth estimation. As illustrated below, we propose a two-stage training strategy: (i) cross-modal distillation from RGB to events and (ii) model adaptation of Vision Foundation Models to operate directly on event data. In the first stage, we leverage a pre-trained Vision Foundation Model (VFM) to generate dense depth pseudo-labels from RGB frames. These labels supervise the training of a student network that learns to estimate depth from corresponding event stacks. This approach eliminates the need for expensive depth ground-truth annotations and enables effective supervision in the event domain.
 |
|
Proposed Cross-Modal Distillation Strategy.
During training, a VFM teacher processes RGB input frames $\mathbf{I}$ to generate proxy depth labels $\mathbf{D}^*$, which supervise an event-based student model. The student takes aligned event stacks $\mathbf{E}$ as input and predicts the final depth map $\mathbf{D}$.
|
|
Labels Distillation from Frame-Based Vision Foundation Model
Given the availability of aligned color and event modalities, e.g., collected by a DAVIS346B sensor, we can exploit a VFM to extract proxy labels from the color images, resulting in much dense supervision compared to the one provided by semi-dense LiDAR annotations.
|
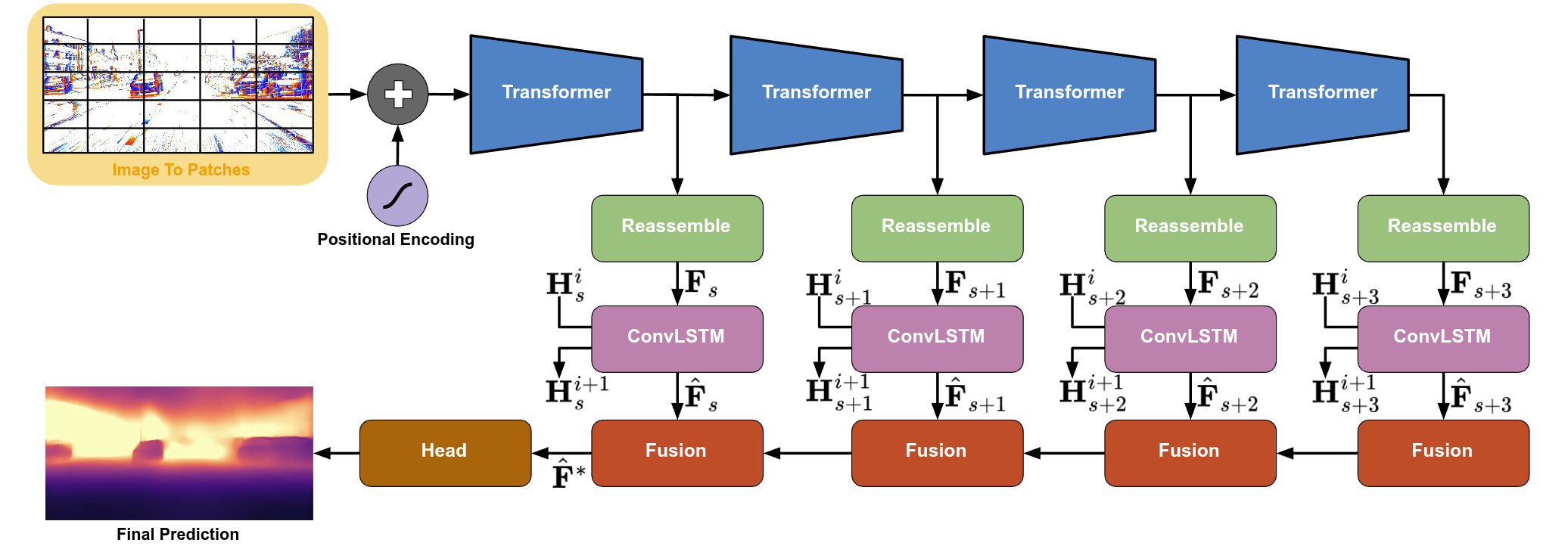
To effectively apply image-based models to events, we encode the sparse asynchronous event stream using the Tencode representation. This converts the temporal and polarity information of events into a 3-channel image that resembles RGB format, making it compatible with existing pre-trained VFMs. In the second part of our pipeline, we explore two adapted architectures: a vanilla model that directly fine-tunes Depth Anything v2 on event representations, and a recurrent variant—DepthAnyEvent-R—which incorporates temporal memory through ConvLSTM blocks. This recurrent design allows the network to process event sequences more effectively, particularly in scenarios with little motion or sparse signal.
 |
|
Proposed Recurrent VFM.
Our DepthAnyEvent-R model processes image patches with positional encoding through multiple transformer stages that produce multi-scale feature maps $\mathbf{F}_s$. These features are combined with hidden states $\mathbf{H}_s^i$ in ConvLSTM modules $\mathcal{R}_s$ to incorporate temporal information from previous event stacks, generating enhanced feature maps $\hat{\mathbf{F}}_s$ and updated hidden states $\mathbf{H}_s^{i+1}$. A hierarchical fusion process integrates features from different scales to predict the final depth prediction $\hat{\mathbf{F}}^*$.
|
|
|
Qualitative Results on DSEC dataset -- Zero-Shot Generalization.
From left to right: event image, predictions by E2Depth, EReFormer, DepthAnyEvent and DepthAnyEvent-R, trained on EventScape only.
|
In zero-shot settings—without any fine-tuning on real-world data—our models generalize significantly better than prior event-based approaches.
|
|
Qualitative Results on MVSEC -- Fine-tuned Models.
From left to right: event image, predictions by E2Depth, EReFormer, DepthAnyEvent and DepthAnyEvent-R, trained on EventScape and fine-tuned on MVSEC.
|
After fine-tuning on MVSEC, all models show improved accuracy, yet our proposed DepthAnyEvent and DepthAnyEvent-R models still outperform existing methods
|
|
Qualitative Results on DSEC -- Supervised vs Distilled Models.
From left to right: event image, predictions by DepthAnyEvent and its distilled counterpart, and by DepthAnyEvent-R and its distilled counterpart.
|
The visual comparison between supervised and distilled models demonstrates that our cross-modal distillation strategy can achieve comparable—or even superior—performance without using expensive ground-truth annotations.
|
BibTeX
InProceedings{Bartolomei_2025_ICCV,
title={Depth AnyEvent: A Cross-Modal Distillation Paradigm for Event-Based Monocular Depth Estimation},
author={Bartolomei, Luca and Mannocci, Enrico and Tosi, Fabio and Poggi, Matteo and Mattoccia, Stefano},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year = {2025},
}




